BLIS: Evolving llm-d at Simulation Speed










Deploying llm-d is not just a question of choosing a model server and adding GPUs. In a production inference deployment, operators have to choose routing policies, admission behavior, batching settings, KV-cache reuse strategies, prefill/decode placement, and autoscaling rules under concrete TTFT, ITL, throughput, and cost constraints.
These choices are coupled. A routing change that improves cache locality can concentrate load. A prefill/decode threshold that helps one workload can hurt another. An admission policy that protects critical traffic can reduce total served volume. A change in any one policy can shift TTFT, inter-token latency, throughput, SLO compliance, and accelerator cost in ways that are difficult to predict analytically.
The only reliable way to confirm those tradeoffs is to measure them in a GPU-backed llm-d cluster. But using cluster runs as the first step in every policy or capacity-planning experiment is too slow and expensive. BLIS provides a faster inner loop: a calibrated discrete-event simulator for distributed inference systems like llm-d. Developers can evaluate candidate policies and deployment configurations locally, then reserve cluster validation for the candidates most likely to matter.
- BLIS is a discrete-event simulator: — it models admission, routing, scheduling, KV cache, batching, and prefill/decode placement without loading model weights or occupying GPUs.
- Calibrated fidelity: Median 7–9% error on end-to-end and inter-token latency across 36 validation experiments spanning 8B–141B parameter models, H100/A100/L40S GPUs, and diverse workloads. Approximately 200× faster than equivalent cluster runs.
- Admission control case study: An AI-native policy-search loop using BLIS discovered a probabilistic admission controller that reduced critical-tier TTFT p90 by up to 97% and end-to-end latency by up to 50%, validated on a real llm-d cluster.
- Capacity planning: BLIS evaluates hundreds of deployment configurations in minutes, producing ranked Pareto-optimal candidates before any GPU time is spent.
The cost of policy search
The case for simulation is strongest when deployment choices form a large search space. In llm-d, that search space includes parallelism strategy, replica topology, routing policy, admission behavior, batching configuration, KV-cache reuse, and prefill/decode placement. Each choice affects the others, so the best configuration is usually workload- and SLO-dependent rather than universal.
The need is especially clear in production-style inference. A useful evaluation often requires realistic request distributions, multi-instance topologies, enough offered load to expose saturation behavior, and repeated runs across policy or configuration variants. These evaluations are subtle because prefill and decode stress the system differently, batching can improve throughput while shifting latency, and disaggregation only helps when transfer cost, queue state, and TTFT/ITL targets line up. BLIS changes the economics of this search:
| BLIS | GPU cluster | |
|---|---|---|
| Wall-clock time per config | ~seconds | ~hours |
| Hardware required | CPU (local) | Multi-GPU (e.g. 4–16× H100) |
| Cost per config | Negligible | GPU-hours at cluster rates |
| Configs evaluated per hour | Hundreds | Single digits |
| Deterministic replay | Yes | No (system jitter, variance) |
Running this search directly on GPU-backed clusters turns policy development into a scarce-resource scheduling problem. BLIS changes the order of operations: broad exploration happens through local simulation, and cluster validation is used later for the small set of policies or configurations that simulation identifies as worth the cluster time.
What is BLIS?
BLIS models the parts of distributed LLM serving that determine system-level behavior: request arrival, admission, routing, queueing, chunked prefill, continuous batching, decode scheduling, KV-cache allocation and reuse, prefill/decode transfer costs, and multi-instance placement. It does not load model weights or execute tensor kernels. Instead, it advances the request lifecycle through a discrete-event simulation driven by performance models fit to real measurements.

BLIS models each stage of the request lifecycle — admission, routing, queueing, chunked prefill, continuous batching, decode scheduling, KV-cache allocation, and P/D transfer — using performance models fit to real GPU measurements. It produces TTFT, inter-token latency, end-to-end latency, throughput, queue depth, SLO violations, shed traffic, and policy rankings without occupying cluster accelerators.
That makes BLIS useful in two different workflows:
- Policy development: compare routing, admission, batching, P/D placement, and autoscaling behavior before implementing or validating the best candidates in production code.
- Capacity planning: sweep hardware budgets and vLLM/llm-d configuration choices to identify the smallest set of real deployments worth benchmarking.
Fidelity and validation
BLIS is not intended to replace cluster validation. Its job is to make exploration cheap enough that developers can search a larger space before scheduling cluster runs. For that to work, BLIS must be accurate enough to identify promising candidates and preserve the relative ranking of alternatives.
In current validation, BLIS shows median 7–9% error on end-to-end and inter-token latency relative to cluster runs. Equivalent cluster experiments take roughly 200× longer to run.
The validation set spans 36 experiments across:
- Models: Dense and MoE architectures from 8B to 141B parameters (Llama, Mixtral, Qwen families)
- Workloads: Chat, code generation, and long-output reasoning
- GPUs: NVIDIA H100, A100, and L40S
- Configuration sweeps: Tensor parallelism and chunk size variations
The most important fidelity question depends on the use case. For capacity planning, absolute latency error matters because SLO boundaries determine feasible configurations. For policy search, rank fidelity is often more important: if policy A beats policy B in BLIS across representative workloads, cluster validation should confirm the same ordering often enough to make simulation a reliable filter.
AI-native evolution of llm-d
AI-native evolution means using agents to propose, test, and refine policies or new algorithms, while reserving cluster validation for the most promising candidates. BLIS is the fast inner loop; a GPU-backed llm-d deployment is the validation outer loop. Developers can connect BLIS to any policy-search workflow — a human-driven sweep, a custom optimizer, or an agentic system — and explore routing, admission, batching, P/D placement, cache behavior, and capacity choices in simulation before validating the strongest candidates on a real cluster. Measurements from cluster runs feed back into calibration, making each round of simulation more accurate. The admission-control case study below shows this pipeline end to end.
Case study: from latency cliffs to graceful admission control
Admission control is a good example of why a simulator is useful. Under overload, default llm-d admission behavior can act like a cliff: requests are admitted until saturation is reached, then sheddable traffic is rejected hard. By the time the threshold fires, queues may already be deep enough to affect protected traffic.
Figure 2 shows how the AI-native pipeline was applied to this problem. BLIS evaluated many candidate admission policies across workload traces, ranked them by SLO compliance, and passed the strongest candidates to cluster validation. Cluster measurements then fed back to calibrate the next round of simulation.

The pipeline narrowed a large policy space to a single winner: a probabilistic admitter that sheds low-priority traffic gradually as saturation rises, protecting critical traffic before the system reaches the cliff. Cluster validation on Qwen3-14B served by vLLM on 4× NVIDIA H100-SXM-80GB GPUs, routed through llm-d, confirmed the improvement:
| Metric (critical tier, overloaded) | Default hard-shed | Probabilistic admitter | Improvement |
|---|---|---|---|
| TTFT p90 | Latency cliff under overload | Smooth degradation | Up to 97% reduction |
| End-to-end latency | Queues build before shed fires | Early shed prevents buildup | Up to 50% reduction |
| Shed behavior | Abrupt rejection at threshold | Gradual shedding as saturation rises | Graceful |

The important point for llm-d is not only the specific admission algorithm. It is the workflow: simulation narrowed a large policy space, cluster validation confirmed the strongest candidate, and the result became a concrete llm-d-router contribution. For the full discovery process, algorithm details, and benchmark matrix, see the admission-controller case study.
Policy space: when to disaggregate prefill and decode
llm-d's current P/D decider uses a fixed prefix-cache threshold: disaggregate any request with more than N=16 uncached tokens. This is cache-aware but queue-blind — it disaggregates at the same rate regardless of whether the prefill pool is idle or saturated.
That threshold is simple and often useful, but it leaves performance on the table when queue state matters more than uncached-token count. A short uncached prompt may not justify KV-transfer overhead even if it crosses the threshold. A long uncached prompt may benefit from disaggregation only when the prefill pool has enough spare capacity to absorb it. The right decision depends on request shape, cache state, queue depth, transfer cost, and SLO pressure.
BLIS lets us evaluate a wider policy space: always-local, always-disaggregate, stationary randomized, fixed threshold, and a dynamic policy we call Empirical Drift-Plus-Penalty (EDPP), derived from Lyapunov optimization. EDPP routes each request using two signals: the relative queue depths of the decode and prefill pools at decision time, and a virtual TTFT queue that accumulates deficit whenever a disaggregated request misses an operator-specified TTFT SLO. When the decode pool is backlogged and the prefill pool has spare capacity, EDPP disaggregates. When prior disaggregation decisions push TTFT past the SLO, the virtual queue grows and suppresses future disaggregation until TTFT recovers. No hardware constants are required; the operator specifies goals, including an ITL target and TTFT SLO, and the policy adapts.
We evaluated on a 1P+3D topology (1 prefill + 3 decode instances) using BLIS's trained-physics latency model configured for Meta Llama 3.1-70B-Instruct on NVIDIA H100 (TP=4 per instance, 16 H100s total), with workloads from the inference-perf catalog:
- Interactive chat: 5K-token prefix, approximately 50 uncached tokens per turn, 4 turns per session. At N=16, the threshold decider disaggregates nearly every turn. Because uncached inputs are short, the KV-transfer round trip adds overhead with little throughput benefit. EDPP disaggregates only when decode backlog makes the transfer worthwhile, reducing mean TTFT by 2-3x at moderate-to-high load in BLIS.
- Code generation: 30K-token prefix, approximately 1,500 uncached tokens per turn, 15 turns per session. At N=16, the threshold fires for 100% of requests. This can saturate the prefill pool and inflate TTFT by up to 20x relative to always-local. EDPP's SLO-feedback loop suppresses disaggregation when TTFT exceeds the target, stabilizing the disaggregation fraction near 50%.
The plot below shows one slice of this policy comparison for the interactive-chat workload.
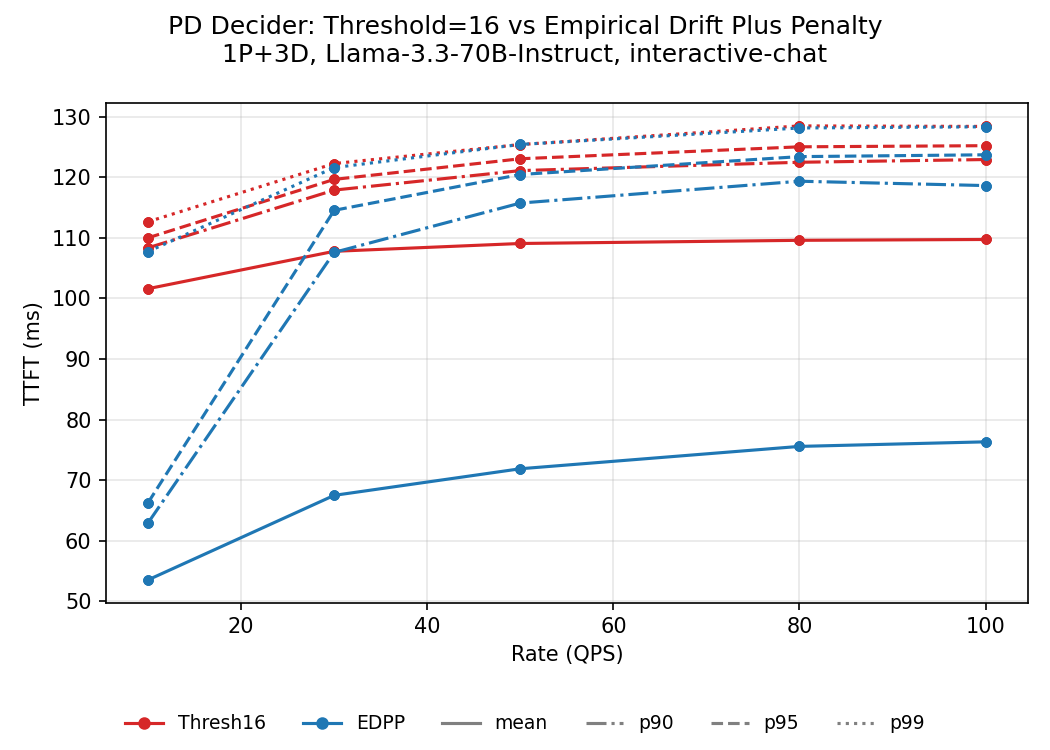
The point is not that BLIS eliminates the need for cluster validation. It makes this kind of policy search practical enough that cluster runs can be reserved for the small number of policies that survive broad simulated evaluation.
Capacity planning
The same simulation loop applies to deployment planning. Before committing cluster time, operators need to know which configurations can plausibly meet a workload's SLO:
- How many GPUs? Which GPU type?
- What configurations meet the SLO?
- Which router knobs — scorer weights, prefix-cache priority, load-balance settings?
- Which vLLM knobs — tensor parallelism, chunk size, batch limits?
Without simulation, each candidate can become a cluster experiment. With BLIS, configuration search becomes a local CPU-based sweep that produces a ranked set of viable options before validation time is spent on the cluster.
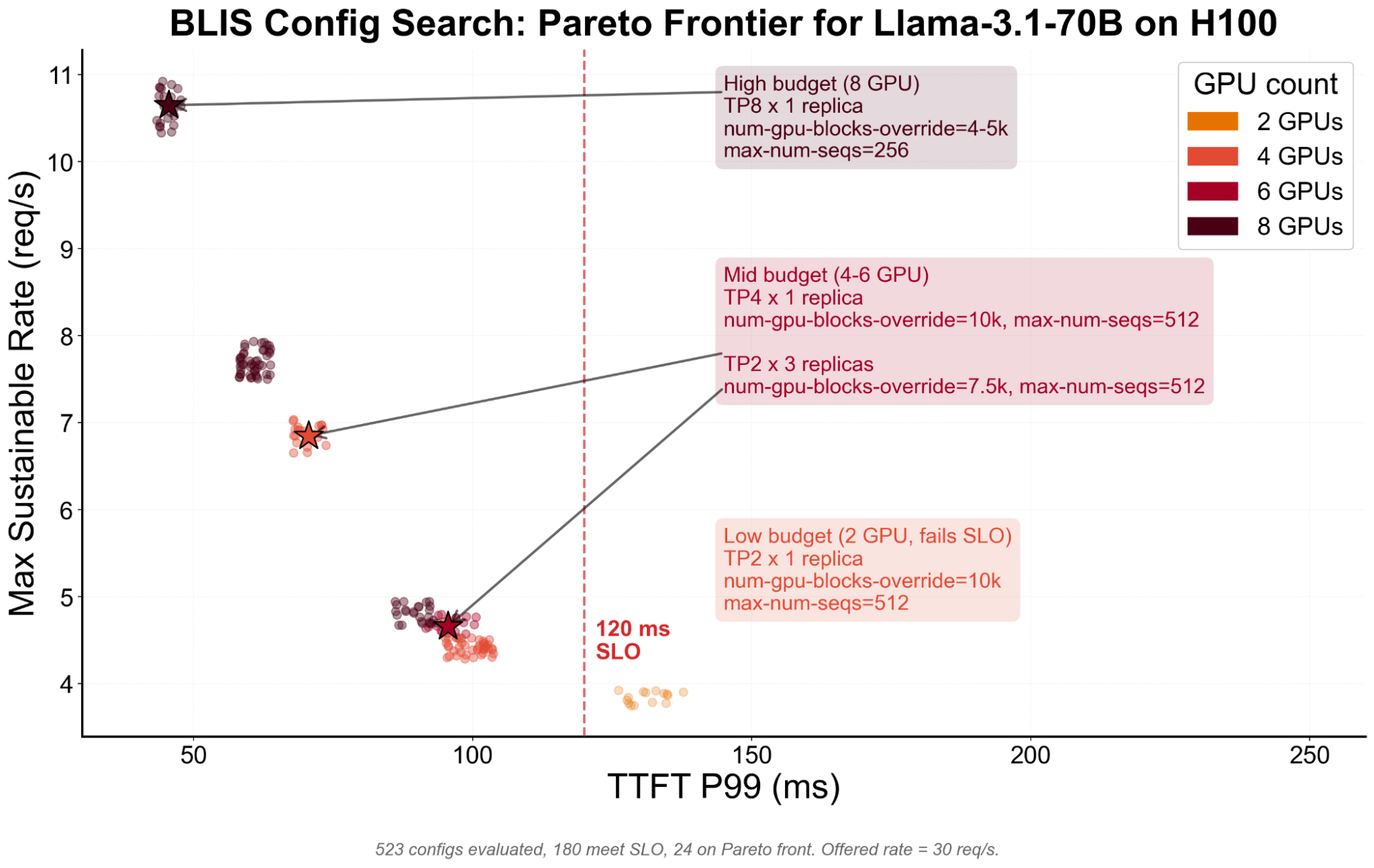
In this kind of view, each dot is a BLIS-evaluated configuration. The x-axis captures latency, the y-axis captures sustainable throughput, and the SLO boundary separates feasible from infeasible candidates. The Pareto frontier identifies the highest-throughput configurations at each feasible latency/cost point, while annotations explain the concrete deployment choices behind selected budget tiers.
This is the role BLIS can play in llm-d capacity planning: not to hand operators a single answer without validation, but to reduce an enormous search space to a short list of explainable candidates.
llm-d-planner, the deployment-recommendation tool for llm-d, is planned to consume BLIS output to power exactly this kind of sizing and policy advice.
Why this matters
llm-d's mission is to make advanced inference optimizations practical for production Kubernetes deployments. That requires more than peak benchmark results. It requires a way to reason about policy interactions, workload sensitivity, and cost before users spend cluster time.
BLIS gives llm-d a fast, deterministic inner loop for that work. Developers can test routing changes, admission policies, batching behavior, prefill/decode decisions, and capacity assumptions in simulation, then reserve cluster runs for the candidates worth validating.
That is the practical shift: cluster validation remains mandatory, but broad cluster exploration becomes targeted. For a project like llm-d, where the control plane is itself a source of performance advantage, that faster inner loop is infrastructure for continued evolution.
Limitations
The following areas highlight current limitations of BLIS:
- Network effects: BLIS models tensor-parallel and data-parallel communication overhead from profiling data, but does not explicitly model the network itself. Real network behavior varies with hardware topology, region, and is subject to jitter — none of which are captured.
- Platform drift: The simulator mirrors vLLM and llm-d behavior at a point in time. As the real stack evolves, the simulator must be updated to stay accurate.
- Selective fidelity: At any point in time, BLIS is not expected to model everything in llm-d and vLLM, but only the most load-bearing aspects of the real system. We focus on a few aspects at a time to improve algorithms in the stack, and those are the aspects prioritized for development in the simulator — on an as-needed-for-policy-evolution basis.
- Saturated regimes: BLIS's performance model is not calibrated for deeply saturated conditions. This is expected — in heavily overloaded systems, small perturbations in arrival or service times cause disproportionate queueing effects, making precise prediction impractical for any simulator. The practical goal is to identify policies that avoid saturation, not to predict behavior within it.
What's next
BLIS is under active development. Key directions include:
- Broader llm-d coverage: Extending the simulator to track new llm-d control-plane features as they land — including autoscaling policies, multi-model routing, and evolving P/D placement strategies.
- Calibration and fidelity: Expanding the validation set to cover new GPU families, larger topologies, and additional workload patterns. Improving performance-model accuracy in near-saturation regimes.
- Integration with llm-d-planner: Connecting BLIS output to llm-d-planner to provide deployment sizing and policy recommendations backed by simulation evidence.
- Community contribution: The upcoming BLIS proposal for llm-d will outline the path for BLIS to become a community-maintained component of the llm-d ecosystem.
Further reading
- BLIS project: inference-sim.github.io/inference-sim
- Why simulate before you scale
- The physics of high-fidelity distributed inference platform simulation
- From simulation to production: the admission controller case study
Get Involved with llm-d
The llm-d project thrives on community contributions, and there are many ways to get involved:
- Explore the code → Browse our GitHub organization and dig into the projects powering this stack
- Join our Slack → Get your invite and connect with maintainers and contributors
- Attend community calls → All meetings are open! Add our public calendar and join the conversation
- Follow project updates → Stay current on Twitter/X, Bluesky, and LinkedIn
- Watch demos and recordings → Subscribe to the llm-d YouTube channel for community call recordings and feature walkthroughs
- Read the docs → Visit our community page to find SIGs, contribution guides, and upcoming events